مطالب اساسی در kafka - راه اندازی Realtime Data Pipeline
جلسه یازدهم: 1400/05/19
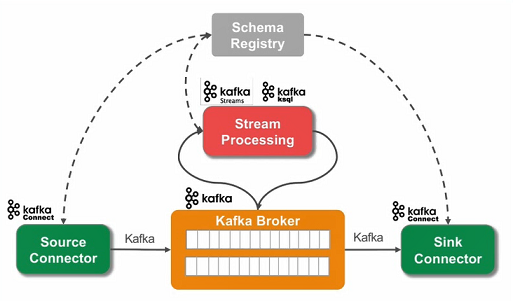
سناریوی اصلی
1- اتصال به دیتابیس مبدا از طریق Source Connector
2- شناسایی تغییرات داده در دیتابیس مبدا و ارسال به Kafka Broker
3- نگهداری موقت داده در Kafka (استفاده از سرویس Schema Registry برای کنترل ساختار)
4 - درصورت نیاز پردازش و اعمال تغییرات
5- انتقال داده ها به دیتابیس مقصد از طریق Sink Connector
* مورد 1 و 2 توسط Source Connector ارائه میشه که خارج از Kafka هست و میتونه روی سرور دیگری هم باشد. ابزار debezium در داخل Source Connector قرار می گیرد (embed) و وظیفه خواندن لاگ های دیتابیس و تحویل آنها را Kafka Connect را دارد.
* مورد 3 که نقش Kafka است و کنترل ساختار را هم که سرویس Schema Registry کمک میکنه
* مورد 4 که توسط Stream Processing انجام میشه (توسط Kafka KSQL یا Kafka Stream)
* مورد 5 را هم وظیفه Sink Connector است و مشابه Source Connector خارج از Kafka انجام شده و میتونه روی سرور دیگری میزبانی بشه
پیشنیازی
* به سرور 192.168.56.12 که mysql برروی آن نصب شده با کاربر root وارد شده و ساعت را با فرمان زیر تنظیم کنید
set global time_zone = "+03:00";
*دستورات ادامه را در محیط mysql اجرا کنید
create database sampledb;
use sampledb;
drop table contacts;
show tables;
CREATE TABLE contacts (
id INT PRIMARY KEY auto_increment,
name VARCHAR(30),
email VARCHAR(30)
);
use sampledb;
insert into contacts (name,email) values ('test1' , 'test1@gmail.com');
insert into contacts (name,email) values ('test2' , 'test2@gmail.com');
insert into contacts (name,email) values ('test3' , 'test3@gmail.com');
commit;
روش اجرا
- اجرای ZooKeeper برروی node-master (اگر به هر علتی مثلا مشکل در فایل cfg استارت نشود گام های بعدی قابل انجام نیست)
/opt/zookeeper/bin/zkServer.sh start
- اجرای Kafka Broker برروی node-master؛ درصورت قرارداد پارامتر daemon- در خط فرمان زیر، سرویس در پس زمینه اجرا می شود
/opt/kafka/bin/kafka-server-start /opt/kafka/etc/kafka/server.properties
- اجرای Connector ها (Source و Sink) برروی node-master (Connector می تواند برروی سرور دیگری باشد)؛ با چندتا فایل کانفیگ properties. استارت میشه که اولی مربوط به خود Kafka Connect Server است و بقیه مربوط به properites. های دیتابیس هایی است باید به آنها متصل شود.
*فولدی /opt/connect_offset/ را ایجاد کنید
*در فایل زیر تغییراتی که در ادامه به آن اشاره می شود را اعمال کنید
/opt/kafka/etc/kafka/connect-standalone.properties
bootstrap.servers=192.168.56.10:9092
offset.storage.file.filename=/opt/connect_offset/connect.offsets
plugin.path=/usr/share/java,/opt/kafka/share/java
* اضافه کردن درایور اتصال به دیتابیس (اینجا برای mysql) به مسیر
/opt/kafka/share/java/kafka-connect-jdbc/
*شامل فایل های
mysql-connector-java-5.1.26.jar
*فایلی به نام mysql-source.properties در مسیر /opt/kafka/etc/kafka-connect-jdbc/رایجاد کنید و مقادیری زیر را درون آن وارد کنید
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://192.168.56.12:3306/sampledb
connection.user=root
connection.password=P@33wordMysql
table.whitelist=contacts
می شود جداول دیگری به whitelist با ویرگول اضافه کرد
mode=incrementing
مقدار mode می تواند پیچیده تر هم باشد مثلا incrementing+timestamp که در اینصورت درادامه مقدار timestamp.column.name=UPDATE_TS را باید افزود.
incrementing.column.name=id
topic.prefix=t_
*و نهایتا اجرای kafka connect به ترتیب زیر برروی node-master
/opt/kafka/bin/connect-standalone /opt/kafka/etc/kafka/connect-standalone.properties /opt/kafka/etc/kafka-connect-jdbc/mysql-source.properties
- اجرای Schema Registry (بعدا)
- اجرای CDC (بعدا)
* ابزار debezium (بعدا)
به منظور تست صحت انجام کار به ترتیب زیر عمل کنید
-به ترتیب زیر consumer kafka اجرا کنید
/opt/kafka/bin/kafka-console-consumer --bootstrap-server node-master:9092 --topic t_contacts --from-beginning
- با اجرای چندین insert برروی دیتابیس mysql و سپس مراجعه به بخش consumer kafka شاهد لاگ شدن مقادیر در kafka خواهید بود.
اضافه کردن Schema Registry Server
- انجام تغییرات در فایل schema-registry.properties به ترتیب زیر
listeners=http://node-master:8081
kafkastore.connection.url=node-master:2181/kafka_znode
- آماده سازی داده در mysql به ترتیب زیر
CREATE TABLE contacts3 (
id INT PRIMARY KEY auto_increment,
name VARCHAR(30),
email VARCHAR(30),
UPDATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
insert into contacts3 (name,email) values ('contact3_name1' , 'contact3_name1@gmail.com');
insert into contacts3 (name,email) values ('contact3_name2' , 'contact3_name2@gmail.com');
insert into contacts3 (name,email) values ('contact3_name3' , 'contact3_name3@gmail.com');
- انجام تغییرات زیر در فایل mysql-source.properties
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://192.168.56.12:3306/sampledb
connection.user=root
connection.password=P@33wordMysql
table.whitelist=contacts3
mode=timestamp+incrementing
timestamp.column.name=UPDATE_TS
incrementing.column.name=id
topic.prefix=t_
key.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://node-master:8081
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://node-master:8081
- اجرای ZooKeeper برروی node-master (اگر به هر علتی مثلا مشکل در فایل cfg استارت نشود گام های بعدی قابل انجام نیست)
/opt/zookeeper/bin/zkServer.sh start
- اجرای Kafka Broker برروی node-master؛ درصورت قرارداد پارامتر daemon- در خط فرمان زیر، سرویس در پس زمینه اجرا می شود
/opt/kafka/bin/kafka-server-start /opt/kafka/etc/kafka/server.properties
- اجرای Schema Registry
/opt/kafka/bin/schema-registry-start /opt/kafka/etc/schema-registry/schema-registry.properties
- اجرای kafka connect
/opt/kafka/bin/connect-standalone /opt/kafka/etc/kafka/connect-standalone.properties /opt/kafka/etc/kafka-connect-jdbc/mysql-source.properties
-به ترتیب زیر consumer kafka اجرا کنید
/opt/kafka/bin/kafka-console-consumer --bootstrap-server node-master:9092 --topic t_contacts3 --from-beginning
- با دستور insert یا update برروی دیتابیس mysql و سپس مراجعه به بخش consumer kafka شاهد لاگ شدن مقادیر در kafka خواهید بود، اما به دلیل فعال بودن Schema Registry از این پس دیتا با فرمت Avro در kafka ذخیره شده و درهنگام consume کردن نمایش داده خواهد شد. برای حل موضوع دستور زیر را اجرا کنید.
/opt/kafka/bin/kafka-avro-console-consumer --bootstrap-server node-master:9092 --topic t_contacts3 --from-beginning --property schema.registry.url=http://node-master:8081 --property print.key=true
استفاده از ابزار Debezium برای CDC
- پیش نیاز: فعال سازی لاگ در mysql؛ مقادیر زیر را در فایل my.cnf در مسیر /etc/ برروی سرور 192.168.56.12 تنظیم کنید. (پیشنهاد به استفاده از vim)
server-id = 1
log_bin = mysql-bin
binlog_format = row
binlog_row_image = full
expire_logs_days = 10
در ادامه mysql را ریست کنید
systemctl stop mysqld
systemctl start mysqld
-پیش نیازی: ایجاد یک جدول جدید
CREATE TABLE contacts_dbz (
id INT PRIMARY KEY auto_increment,
name VARCHAR(30),
email VARCHAR(30)
);
- راه اندازی Debezium؛ فایل debezium-connector-mysql-1.6.1.Final-plugin.tar.gz را دانلود و در محیط ویندوز بازکنید، از محتویات باز شده تمامی فایل های jar را در مسیر زیر کپی کنید
/opt/kafka/share/java/kafka-connect-jdbc/
- برای ایجاد فایل properties برای Devezium، در مسیر /opt/kafka/etc/kafka-connect-jdbc/ فایلی بنام mysql-source-dbz.properties بسازید و مقادیر زیر را در آن درج کنید
name=mysql-connector-flattened
connector.class=io.debezium.connector.mysql.MySqlConnector
database.hostname=192.168.56.12
database.port=3306
database.user=root
database.password=P@33wordMysql
database.server.id=5550
database.server.name=k5550
table.whitelist=sampledb.contacts_dbz
database.history.kafka.bootstrap.servers=node-master:9092
database.history.kafka.topic=dbhistory.k555
include.schema.changes=true
transforms=unwrap,changetopic
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.changetopic.type:org.apache.kafka.connect.transforms.RegexRouter
transforms.changetopic.regex:(.*)
transforms.changetopic.replacement:$1_cdc
key.converter:io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url:http://node-master:8081
value.converter:io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url:http://node-master:8081
deletes.enabled=true
pk.mode=record_key
transforms.unwrap.drop.tombstones=false
- پارامتر آخر یعنی transforms.unwrap.drop.tombstones اگر false باشد به این معناست که هنگام حذف رکورد به غیر از کلید، سایر فیلدهای اطلاعاتی رکورد حذف شده را نیز در اختیار قرار دهند
- در نهایت kafka connect را با مقادیر زیر وارد کنید
/opt/kafka/bin/connect-standalone /opt/kafka/etc/kafka/connect-standalone.properties /opt/kafka/etc/kafka-connect-jdbc/mysql-source-dbz.properties
- consume کردن در kafka را به ترتیب زیر انجام دهید
/opt/kafka/bin/kafka-avro-console-consumer --bootstrap-server node-master:9092 --topic k5550.sampledb.contacts_dbz_cdc --from-beginning --property schema.registry.url=http://node-master:8081 --property print.key=true
- برای تست اجرا کافیست عبارات زیر در mysql اجرا شده و اثرات آن با kafka-console-consumer بررسی شود
insert into contacts_dbz (name,email) values ('contact_name1' , 'contact_name1@gmail.com');
insert into contacts_dbz (name,email) values ('contact_name2' , 'contact_name2@gmail.com');
insert into contacts_dbz (name,email) values ('contact_name3' , 'contact_name3@gmail.com');
insert into contacts_dbz (name,email) values ('contact_name4' , 'contact_name4@gmail.com');
* یکی از تفاوت های ارتباط از طریق debezium با ارتباط عادی با دیتابیس آن است که هنگام خواند لاگ مقدار کلید هم برگردانده شده و به این ترتیب در این وضعیت امکان partitioning در kafka صورت می پذیرد.
استفاده از ابزار Debezium برای Sync
- با فرمان زیر اطلاعات از topic مورد نظر واکشی شده و به جدول از دیتابیس مقصد ارسال می شود. در اینجا همان سرور، همان دیتابیس و فقط جدول دیگر است. در اجرای فرمان زیر دیگر نیازی به استارت مجدد connect نیست.
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://node-master:8083/connectors/ \
-d '{
"name": "dbz-cdc_sink_mysql",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:mysql://192.168.56.12:3306/sampledb",
"tasks.max": "1",
"connection.user": "root",
"connection.password": "P@33wordMysql",
"topics": "k5550.sampledb.contacts_dbz_cdc",
"auto.create": "true",
"transforms": "unwrap,changetopic",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.changetopic.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.changetopic.regex":"k5550[.](.*)",
"transforms.changetopic.replacement":"$1_result",
"key.converter":"io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url":"http://node-master:8081",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://node-master:8081",
"transforms.unwrap.drop.tombstones": "false",
"insert.mode": "upsert",
"pk.fields": "id",
"pk.mode": "record_key",
"delete.enabled": "true"
}
}'
** درصورتیکه سناریو را تا اینجا با موفقیت انجام داده باشید، خواهید دید که هرتغییری در contacts_cdc به شکل خودکار به contacts_dbz_cdc_result منتقل می شود.
- در ادامه مقصد hdfs بوده و دیتا در آنجا sync خواهد شد